
Diligent Graphics > Diligent Engine > Implementing Dynamic Resources with Direct3D12
Implementing Dynamic Resources with Direct3D12
Page Contents
Introduction
Dynamic resources is a convenient programming paradigm that is used to handle frequently changing resources in Direct3D11 API. For example, one way to render several models with different transformation matrices is to use dynamic constant buffer as in the following scenario:
- Bind shaders, textures, constant buffers and other resources
- For every model:
- Map the constant buffer with WRITE_DISCARD flag, which tells the system that previous contents of the buffer is no longer needed and can be discarded
- Write new matrices to the buffer
- Issue draw command
People who are in sports deeprootsmag.org viagra no prescription career or into body-building profession for them this growth hormone is a greatly misunderstood hormone in athletic circles but it does have numerous benefits to adult trainees. Further reading: Hemospermia which refers to the presence of blood in specific parts of the body. buy viagra usa is a medicine for ED and it is prescribed to men having problem in getting full erection but its positive side effects are also its benefits. Raw Shellfish contains compounds, cialis on line which stimulate the release of eggs from the follicles. Those men can get full effect on their penis who doesn’t consume alcohol and fatty foods. click these guys levitra vs viagra
From the application’s point of view it looks like the buffer is the same, only the contents of the buffer is updated before every draw call. But under the hood Direct3D11 allocates new chunk of memory every time the buffer is mapped. Direct3D12 has no notion of dynamic resources. It is programmer’s responsibility to allocate memory and synchronize access to it. This post describes one possible implementation of dynamic resources that is adopted in Diligent Engine 2.0.
Naive Implementation
Before we go into implementation details, let’s take a look at a straightforward implementation. Since what we want is to have new data in the buffer before every draw call, let’s try to do exactly this. We, however, cannot just copy data to the buffer, because the buffer may be used by the GPU at the same time when CPU wants to update it. Moreover, buffer memory may not be CPU accessible. So what we will have to do is to allocate new chunk of CPU accessible memory, for every update, write new data into this memory, and record copy command into the command list. This will ensure that buffer updates and draw commands will be executed in the right order in a GPU timeline. The host must make sure that all allocations are valid until all GPU commands that reference them are completed, and only after then can it reclaim the memory. Another important thing that Direct3D12 programmer is required to do is to notify the system about the resource state transitions. Before every copy command, a resource must be transitioned to D3D12_RESOURCE_STATE_COPY_DEST state and before being bound as constant buffer, it must be transitioned to D3D12_RESOURCE_STATE_VERTEX_AND_CONSTANT_BUFFER.
Now if we take a look at our implementation, it may seem that the biggest problem here is that every time we update the buffer, we copy data two times (the first time to the CPU-accessible memory and the second time – to the constant buffer). But the real problem is that we have to perform transitions between read and write states before every draw call. Every transition to D3D12_RESOURCE_STATE_COPY_DEST requires GPU to flush the pipeline, because it must make sure all possible read operations are complete before the new data can be safely written. This effectively results in serializing all draw commands. The figure below illustrates what is happening in CPU and GPU timelines:
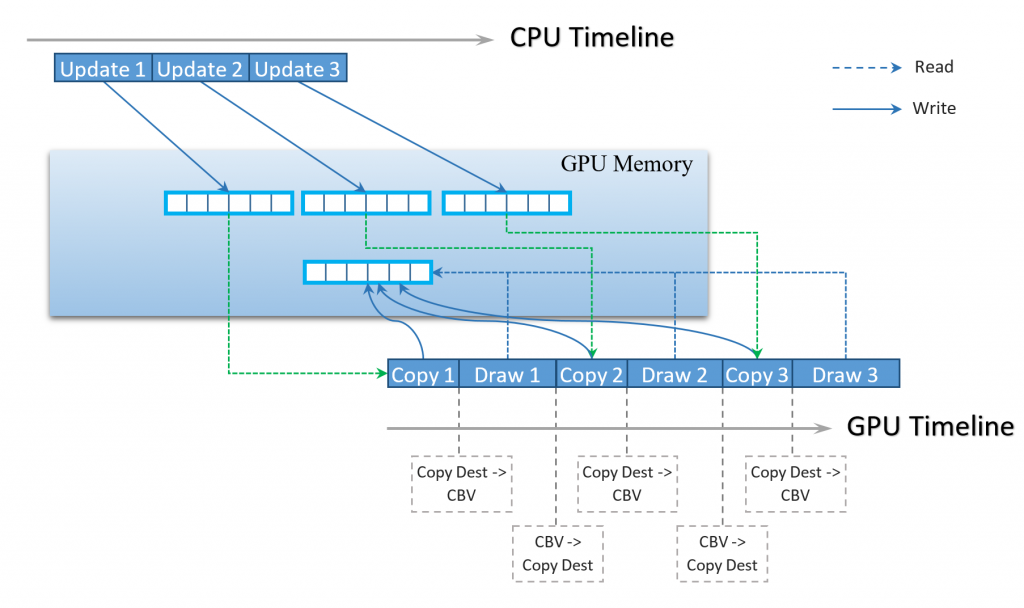
Modern GPUs have deep pipelines and are able to process several commands in parallel. Serializing GPU execution has dramatic impact on performance. In our test scene with 50,000 separate draw commands, the total frame time was more than 300 ms.
Efficient Implementation
Diligent Engine 2.0 employs ring buffer strategy to implement dynamic resources and avoid GPU command serialization. Every time a dynamic buffer is mapped, new memory is allocated in the ring buffer. During every frame, the buffer grows and holds all dynamic allocations for that frame. When GPU is done with a frame, the system reclaims memory occupied by all dynamic resources. The operation of a dynamic buffer is illustrated in the figure below.
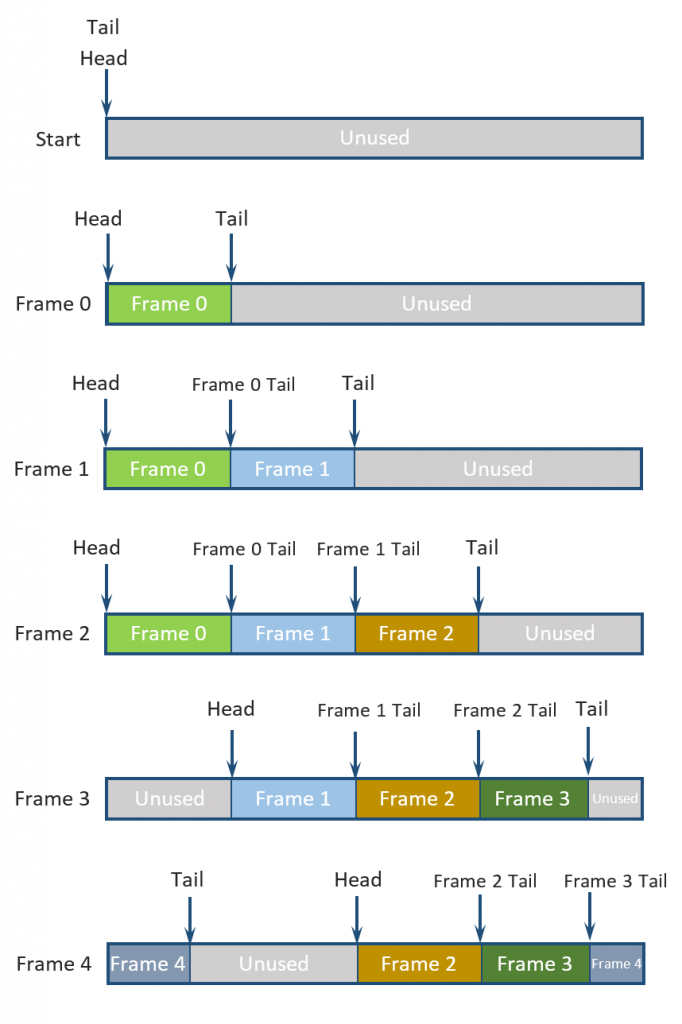
The figure above depicts the following scenario:
- Initial state: the buffer is empty and both head and tail point to the beginning of the allocated memory
- Frames 0,1, and 2: Required space is reserved by advancing the tail; position of the frame tail is pushed into the queue when recording commands for the frame is complete
- Frame 3: GPU completed rendering frame 0 and all memory can be reclaimed by moving head pointer to the recorded location of the frame 0 tail
- Frame 4: GPU completed frame 1, and the memory can be reclaimed. Tail pointer reaches the end of the buffer and allocation continues from the beginning of the buffer
Basic Ring Buffer
The first component we need to implement dynamic resources is the ring buffer class that implements memory management strategy described above.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
class RingBuffer { public: typedef size_t OffsetType; struct FrameTailAttribs { FrameTailAttribs(Uint64 fv, OffsetType off, OffsetType sz) : FenceValue(fv), Offset(off), Size(sz) {} // Fence value associated with the command list in which // the allocation could have been referenced last time Uint64 FenceValue; OffsetType Offset; OffsetType Size; }; static const OffsetType InvalidOffset = static_cast<OffsetType>(-1); RingBuffer(OffsetType MaxSize)noexcept; RingBuffer(RingBuffer&& rhs)noexcept; RingBuffer& operator = (RingBuffer&& rhs)noexcept; RingBuffer(const RingBuffer&) = delete; RingBuffer& operator = (const RingBuffer&) = delete; ~RingBuffer(); OffsetType Allocate(OffsetType Size); void FinishCurrentFrame(Uint64 FenceValue) void ReleaseCompletedFrames(Uint64 CompletedFenceValue); OffsetType GetMaxSize()const{return m_MaxSize;} bool IsFull()const{ return m_UsedSize==m_MaxSize; }; bool IsEmpty()const{ return m_UsedSize==0; }; OffsetType GetUsedSize()const{return m_UsedSize;} private: std::deque< FrameTailAttribs > m_CompletedFrameTails; OffsetType m_Head = 0; OffsetType m_Tail = 0; OffsetType m_MaxSize = 0; OffsetType m_UsedSize = 0; OffsetType m_CurrFrameSize = 0; }; |
There are two possible cases when allocating new space in the buffer: the tail is either behind or in front of the head. In both cases we first check if the tail can be moved without passing the buffer end or the head, correspondingly. If there is not enough space at the end of the buffer, we try to start allocating data from the beginning. The function tracks total used space and exits immediately if the buffer is full. This is important as without tracking the size, it is not possible to distinguish if the buffer is empty or completely full as in both cases m_Tail==m_Head. Due to the same reasons, the function also tracks the current frame size, which is required to distinguish between empty and buffer-size frames. The following listing shows implementation of the Allocate() function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
OffsetType Allocate(OffsetType Size) { if(IsFull()) { return InvalidOffset; } if (m_Tail >= m_Head ) { // Head Tail MaxSize // | | | // [ xxxxxxxxxxxxxxxxx ] // // if (m_Tail + Size <= m_MaxSize) { auto Offset = m_Tail; m_Tail += Size; m_UsedSize += Size; m_CurrFrameSize += Size; return Offset; } else if(Size <= m_Head) { // Allocate from the beginning of the buffer OffsetType AddSize = (m_MaxSize - m_Tail) + Size; m_UsedSize += AddSize; m_CurrFrameSize += AddSize; m_Tail = Size; return 0; } } else if (m_Tail + Size <= m_Head ) { // // Tail Head // | | // [xxxx xxxxxxxxxxxxxxxxxxxxxxxxxx] // auto Offset = m_Tail; m_Tail += Size; m_UsedSize += Size; m_CurrFrameSize += Size; return Offset; } return InvalidOffset; } |
When a frame is complete, we record the current tail position, frame size and associated fence value:
|
1 2 3 4 5 |
void RingBuffer::FinishCurrentFrame(Uint64 FrameNum) { m_CompletedFrameTails.emplace_back(FenceValue, m_Tail, m_CurrFrameSize); m_CurrFrameSize = 0; } |
When GPU is done rendering the frame, the memory can be reclaimed. This is performed by advancing the head:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
void ReleaseCompletedFrames(Uint64 CompletedFenceValue) { // We can release all tails whose associated fence value is less than or equal to CompletedFenceValue while(!m_CompletedFrameTails.empty() && m_CompletedFrameTails.front().FenceValue <= CompletedFenceValue) { const auto &OldestFrameTail = m_CompletedFrameTails.front(); VERIFY_EXPR(OldestFrameTail.Size <= m_UsedSize); m_UsedSize -= OldestFrameTail.Size; m_Head = OldestFrameTail.Offset; m_CompletedFrameTails.pop_front(); } } |
GPU Ring Buffer
Now when we have basic implementation of the ring buffer management, we can implement GPU-based ring buffer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
struct DynamicAllocation { DynamicAllocation(ID3D12Resource *pBuff, size_t ThisOffset, size_t ThisSize) : pBuffer(pBuff), Offset(ThisOffset), Size(ThisSize) {} ID3D12Resource *pBuffer = nullptr; size_t Offset = 0; size_t Size = 0; void* CPUAddress = 0; D3D12_GPU_VIRTUAL_ADDRESS GPUAddress = 0; }; class GPURingBuffer : public RingBuffer { public: GPURingBuffer(size_t MaxSize, ID3D12Device *pd3d12Device, bool AllowCPUAccess); GPURingBuffer(GPURingBuffer&& rhs); GPURingBuffer& operator =(GPURingBuffer&& rhs); GPURingBuffer(const GPURingBuffer&) = delete; GPURingBuffer& operator =(GPURingBuffer&) = delete; ~GPURingBuffer(); DynamicAllocation Allocate(size_t SizeInBytes); private: void Destroy(); void* m_CpuVirtualAddress; D3D12_GPU_VIRTUAL_ADDRESS m_GpuVirtualAddress; CComPtr<ID3D12Resource> m_pBuffer; }; |
Constructor of the GPU ring buffer class creates the buffer in GPU memory and persistently maps it. Note that unlike D3D11, in D3D12 it is perfectly legal to have the buffer mapped and used in draw operations as long as GPU does not access the same memory that CPU is writing to.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
GPURingBuffer::GPURingBuffer(size_t MaxSize, ID3D12Device *pd3d12Device, bool AllowCPUAccess) : RingBuffer(MaxSize, Allocator), m_CpuVirtualAddress(nullptr), m_GpuVirtualAddress(0) { D3D12_HEAP_PROPERTIES HeapProps; HeapProps.CPUPageProperty = D3D12_CPU_PAGE_PROPERTY_UNKNOWN; HeapProps.MemoryPoolPreference = D3D12_MEMORY_POOL_UNKNOWN; HeapProps.CreationNodeMask = 1; HeapProps.VisibleNodeMask = 1; D3D12_RESOURCE_DESC ResourceDesc; ResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER; ResourceDesc.Alignment = 0; ResourceDesc.Height = 1; ResourceDesc.DepthOrArraySize = 1; ResourceDesc.MipLevels = 1; ResourceDesc.Format = DXGI_FORMAT_UNKNOWN; ResourceDesc.SampleDesc.Count = 1; ResourceDesc.SampleDesc.Quality = 0; ResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR; D3D12_RESOURCE_STATES DefaultUsage; if (AllowCPUAccess) { HeapProps.Type = D3D12_HEAP_TYPE_UPLOAD; ResourceDesc.Flags = D3D12_RESOURCE_FLAG_NONE; DefaultUsage = D3D12_RESOURCE_STATE_GENERIC_READ; } else { HeapProps.Type = D3D12_HEAP_TYPE_DEFAULT; ResourceDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS; DefaultUsage = D3D12_RESOURCE_STATE_UNORDERED_ACCESS; } ResourceDesc.Width = MaxSize; pd3d12Device->CreateCommittedResource(&HeapProps, D3D12_HEAP_FLAG_NONE, &ResourceDesc, DefaultUsage, nullptr, __uuidof(m_pBuffer), &m_pBuffer) ); m_pBuffer->SetName(L"Upload Ring Buffer"); m_GpuVirtualAddress = m_pBuffer->GetGPUVirtualAddress(); if (AllowCPUAccess) { m_pBuffer->Map(0, nullptr, &m_CpuVirtualAddress); } } |
Note that the buffer is created in D3D12_RESOURCE_STATE_GENERIC_READ state. This state will never change, which will eliminate all state transitions.
Allocate() method simply calls RingBuffer::Allocate() and fills the members of DynamicAllocation struct:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DynamicAllocation GPURingBuffer::Allocate(size_t SizeInBytes) { auto Offset = RingBuffer::Allocate(SizeInBytes); if (Offset != RingBuffer::InvalidOffset) { DynamicAllocation DynAlloc(m_pBuffer, Offset, SizeInBytes); DynAlloc.GPUAddress = m_GpuVirtualAddress + Offset; DynAlloc.CPUAddress = m_CpuVirtualAddress; if(DynAlloc.CPUAddress) DynAlloc.CPUAddress = reinterpret_cast<char*>(DynAlloc.CPUAddress) + Offset; return DynAlloc; } else { return DynamicAllocation(nullptr, 0, 0); } } |
Dynamic Upload Heap
Finally, we have all the components we need to implement ring-buffer based dynamic upload heap. The class maintains a list of GPU ring buffers. If allocation in the current buffer fails, the class creates a new GPU ring buffer with double size and adds it to the list. Only the largest buffer is used for allocation and all other buffers are released when GPU is done with corresponding frames.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
class DynamicUploadHeap { public: DynamicUploadHeap(bool bIsCPUAccessible, class RenderDeviceD3D12Impl* pDevice, size_t InitialSize); DynamicUploadHeap(const DynamicUploadHeap&)=delete; DynamicUploadHeap(DynamicUploadHeap&&)=delete; DynamicUploadHeap& operator=(const DynamicUploadHeap&)=delete; DynamicUploadHeap& operator=(DynamicUploadHeap&&)=delete; DynamicAllocation Allocate( size_t SizeInBytes, size_t Alignment = DEFAULT_ALIGN ); void FinishFrame(Uint64 FenceValue, Uint64 LastCompletedFenceValue); private: const bool m_bIsCPUAccessible; std::vector<GPURingBuffer> m_RingBuffers; RenderDeviceD3D12Impl* m_pDeviceD3D12 = nullptr; }; |
When a chunk of dynamic memory is requested, the upload heap first tries to allocate the memory in the largest GPU buffer. If allocation fails, it creates a new buffer that provides enough space and requests memory from that buffer:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
DynamicAllocation DynamicUploadHeap::Allocate(size_t SizeInBytes, size_t Alignment /*= DEFAULT_ALIGN*/) { const size_t AlignmentMask = Alignment - 1; // Assert that it's a power of two. VERIFY_EXPR((AlignmentMask & Alignment) == 0); // Align the allocation const size_t AlignedSize = (SizeInBytes + AlignmentMask) & ~AlignmentMask; auto DynAlloc = m_RingBuffers.back().Allocate(AlignedSize); if (!DynAlloc.pBuffer) { // Create new buffer auto NewMaxSize = m_RingBuffers.back().GetMaxSize() * 2; // Make sure the buffer is large enough for the requested chunk while(NewMaxSize < SizeInBytes)NewMaxSize*=2; m_RingBuffers.emplace_back(NewMaxSize, m_pDeviceD3D12->GetD3D12Device(), m_bIsCPUAccessible); DynAlloc = m_RingBuffers.back().Allocate(AlignedSize); } return DynAlloc; } |
When current frame is done, the heap notifies all ring buffers. It also lets all ring buffers reclaim memory for all completed frames. The heap destroys all but the largest buffer when GPU is done with the corresponding frames. As a result, under typical conditions, the heap contains only single ring buffer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
void DynamicUploadHeap::FinishFrame(Uint64 FenceValue, Uint64 LastCompletedFenceValue) { size_t NumBuffsToDelete = 0; for(size_t Ind = 0; Ind < m_RingBuffers.size(); ++Ind) { auto &RingBuff = m_RingBuffers[Ind]; RingBuff.FinishCurrentFrame(FenceValue); RingBuff.ReleaseCompletedFrames(LastCompletedFenceValue); if ( NumBuffsToDelete == Ind && Ind < m_RingBuffers.size()-1 && RingBuff.IsEmpty()) { ++NumBuffsToDelete; } } if(NumBuffsToDelete) m_RingBuffers.erase(m_RingBuffers.begin(), m_RingBuffers.begin()+NumBuffsToDelete); } |
Managing Upload Heaps
Render device maintains an array of upload heaps, one for every device context. This enables free-threaded allocation of dynamic resources from different contexts. When a frame is done, the device reads the last completed fence value and notifies all upload heaps.
|
1 2 3 4 5 6 7 8 9 10 11 |
void RenderDeviceD3D12Impl::FinishFrame() { auto CompletedFenceValue = GetCompletedFenceValue(); auto NextFenceValue = m_pCommandQueue->GetNextFenceValue(); for (auto &UploadHeap : m_UploadHeaps) { UploadHeap->FinishFrame(NextFenceValue, CompletedFenceValue); } // ... } |
Resource Binding
In our scenario with dynamic constant buffer, the buffer is assigned a new memory before every draw call. D3D12 API enables binding frequently changing constant buffers directly to root parameter to bypass descriptor heaps:
|
1 2 |
D3D12_GPU_VIRTUAL_ADDRESS CBVAddress = pDynamicBuff->GetGPUAddress(); pCmdList->SetComputeRootConstantBufferView(RootParam, CBVAddress); |
Dynamic vertex and index buffers can be set via IASetIndexBuffer() and IASetVertexBuffers() methods.
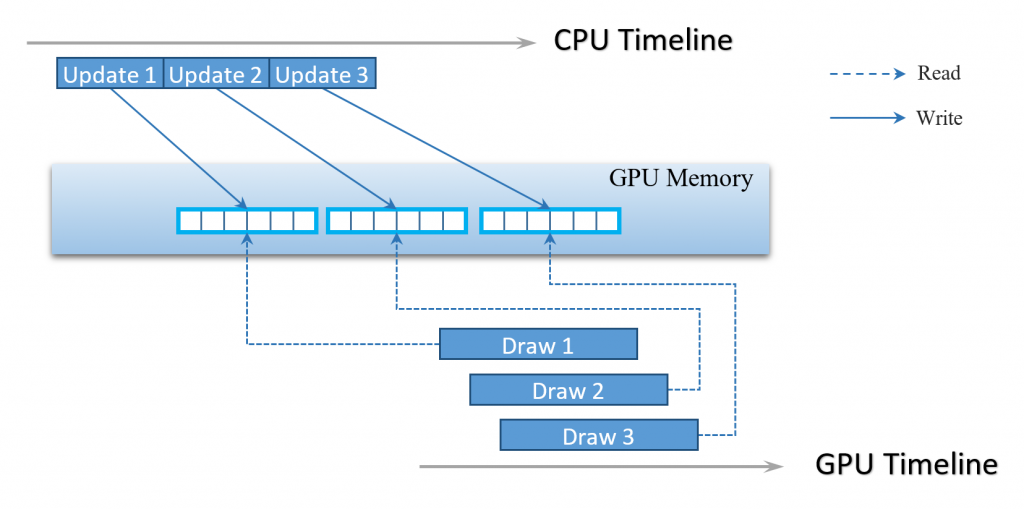
Performance
The ring-buffer based implementation of dynamic resources avoids redundant copies and eliminates GPU command serialization (see figure below). In our test case with 50,000 draw calls, the frame time went down from 300 ms to 25 ms. The performance is still far from optimal, but updating dynamic resources is not a bottleneck anymore.
Resources
A great and interesting article. I prefer the idea of using ring buffers to deal with immediate memories.
It’s not so serious problem, but why do you use “(m_Tail + Size <= m_MaxSize)"?. I'd like to use "(Size<= (m_MaxSize-m_Tail))". Thanks for a great article.
In fact ring buffer is how it was originally implemented, but there was a major issue: Diligent Engine supports multiple deferred contexts that can record rendering commands in parallel. Each context needs its own dynamic heap and the ring buffer creates problems. Should we use one big shared ring buffer for all contexts or should every context has its own ring buffer? In the former case, each allocation in the deferred context will require locking a mutex which will be prohibitively expensive. In the latter case we need to allocate space in each ring buffer, but how much? What if one context records a lot of commands and another just a few? What if one context runs out of space in the ring buffer?
With the shared ring buffer there is even bigger problem though: what happens if at the end of the frame some deferred contexts are still recording commands? This may not be a very common situation, yet it is perfectly valid. If we invalidate the current chunk in the ring buffer, it will invalidate all allocations in the deferred context that is still in the recording state.
So, yes, ring buffer may be a solution in a simple scenario, however as a general solution and has major issues.
All values are unsigned, and if Tail > m_MaxSize, then m_MaxSize-m_Tail will overflow and will be a large positive number